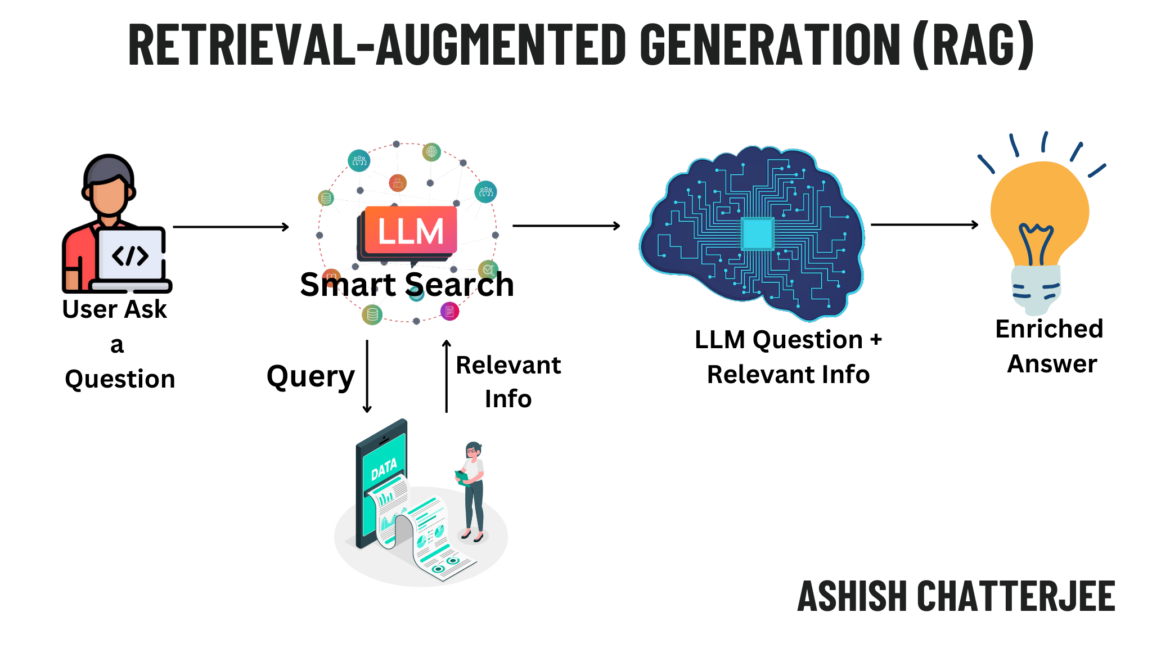
Introduction
Retrieval-Augmented Generation (RAG) is an advanced AI technique that combines information retrieval and text generation to enhance the accuracy and relevance of responses from language models. Unlike traditional language models that rely solely on pre-trained knowledge, RAG dynamically fetches relevant external information before generating a response. This approach is especially useful in applications where factual correctness, real-time updates, and domain-specific knowledge are critical.
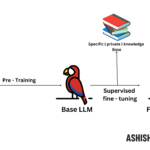
How RAG Works
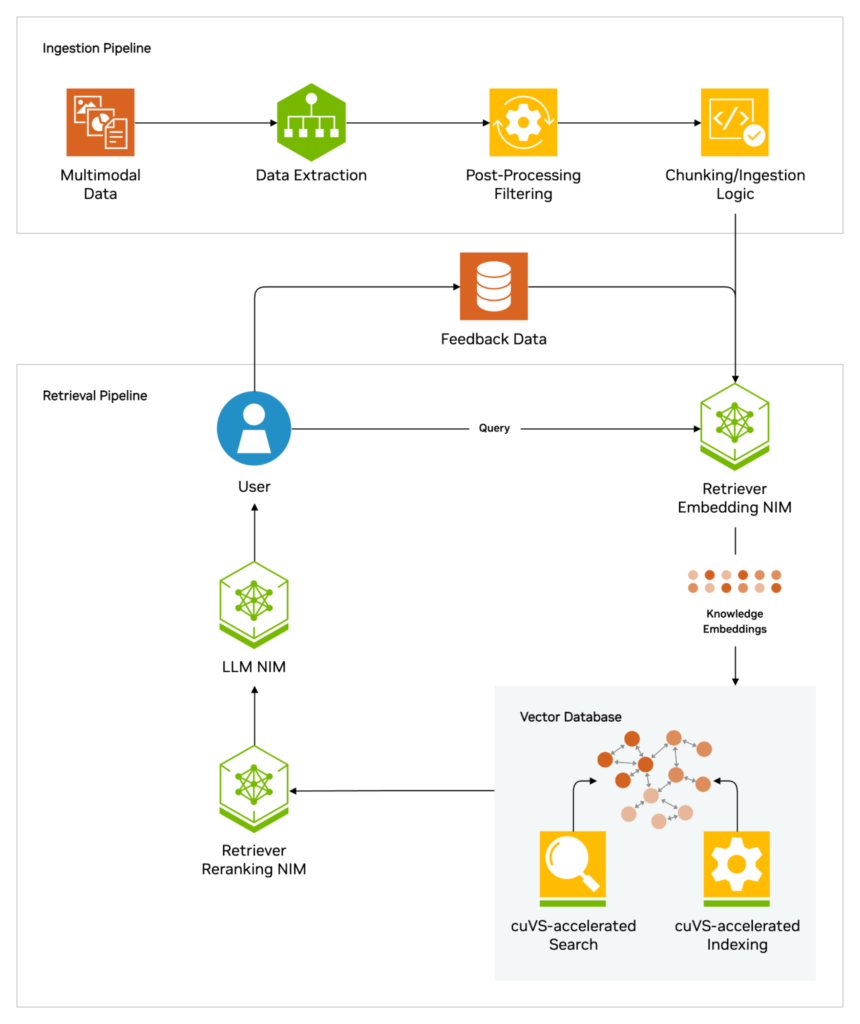
Pic Credits from NVIDIA

RAG operates in two primary phases:
- Retrieval Phase
- The system first processes the user query and searches an external knowledge source (e.g., a database, vector search engine, or web search API).
- It retrieves relevant documents, articles, or snippets that contain useful context related to the query.
- Generation Phase
- The retrieved documents are fed into a language model (such as GPT or BERT-based transformers).
- The model synthesizes the retrieved information and generates a well-informed, contextually accurate response.
This hybrid approach enables RAG to overcome the limitations of static knowledge in pre-trained models, ensuring responses are up-to-date and grounded in reliable sources.
Example of RAG in Action
Scenario: Answering Real-Time Financial Queries
Traditional LLM Approach
- If you ask a static language model, “What is the current stock price of Tesla?”, it might respond with outdated or generalized information because its training data is not updated in real time.
RAG Approach
- With RAG, the system queries a real-time financial database (e.g., Bloomberg API or Yahoo Finance) to retrieve the latest stock price before generating an accurate response.
✅ Example Response:
“As of today, Tesla’s stock price is $620.45 according to Yahoo Finance.”
Use Cases of RAG
1. Enterprise Search & Knowledge Management
- Employees in large organizations often struggle to find relevant information across vast internal documentation.
- RAG-powered assistants can pull information from internal knowledge bases, wikis, and reports to provide precise answers.
🔹 Example: A legal firm using RAG to extract relevant case laws and legal precedents from vast repositories.
2. Customer Support & Chatbots
- Traditional chatbots rely on predefined responses and struggle with complex queries.
- RAG allows chatbots to fetch and generate real-time responses from product manuals, FAQs, and support tickets.
🔹 Example: An e-commerce chatbot using RAG to provide instant answers from a dynamic product catalog.
3. Medical & Healthcare Applications
- Medical professionals require up-to-date information about diseases, drug interactions, and treatment protocols.
- RAG can retrieve the latest research papers and guidelines before responding.
🔹 Example: A medical assistant fetching recent studies on COVID-19 treatment from PubMed before generating a response.
4. Legal Document Analysis
- Lawyers and law firms need to extract relevant clauses and case laws from thousands of documents.
- RAG can streamline this by retrieving case references and summarizing relevant legal text.
🔹 Example: A legal research tool retrieving the latest amendments to tax laws.
5. Academic & Scientific Research
- Researchers can benefit from RAG by pulling information from scientific databases.
- Instead of manually searching for papers, a RAG-powered system can retrieve relevant citations automatically.
🔹 Example: A PhD student using a RAG-powered assistant to find recent research on quantum computing.
Implementing RAG with Google Cloud
Google Cloud offers multiple solutions for building and deploying RAG systems. Some key resources include:
- Using Vertex AI to Build Next-Gen Search Applications
- Vertex AI provides an integrated platform to develop AI models that leverage RAG.
- It enables retrieval from Google Search technology, databases, and vector search systems.
- RAG with Databases on Google Cloud
- Allows retrieval from structured and unstructured data sources, including BigQuery and AlloyDB for PostgreSQL.
- APIs for Building Custom RAG Systems
- Google Cloud offers APIs that developers can use to integrate RAG capabilities into their applications.
- Infrastructure for RAG-powered Generative AI
- Google provides infrastructure solutions using Vertex AI, GKE (Google Kubernetes Engine), and AlloyDB.
- These allow organizations to build scalable and efficient RAG systems.
The Importance of RAG for Business Applications
Despite the general effectiveness of pre-trained LLMs, they often struggle in business environments for several reasons, including:
AI Hallucination: The tendency of LLMs to generate incorrect or fabricated responses, particularly in specialized domains.
Lack of Context: LLMs may not always produce relevant answers due to a lack of domain-specific training data.
Static Data: Without regular updates, LLMs can quickly become outdated, leading to inaccuracies in responses.
RAG addresses these issues by providing LLMs with access to current, domain-specific data, thereby enhancing the accuracy, relevance, and reliability of their outputs.
The Benefits of RAG
Implementing RAG brings numerous advantages, including:
Updated Information: By continuously feeding LLMs with the latest data, RAG ensures that the information provided is current.
Increased Accuracy: Access to a reliable data source reduces the risk of inaccuracies and “hallucinations.”
Enhanced User Trust: RAG enables LLMs to cite the sources of their information, adding a layer of transparency and trust.
How RAG Works
The process of RAG involves three main steps:
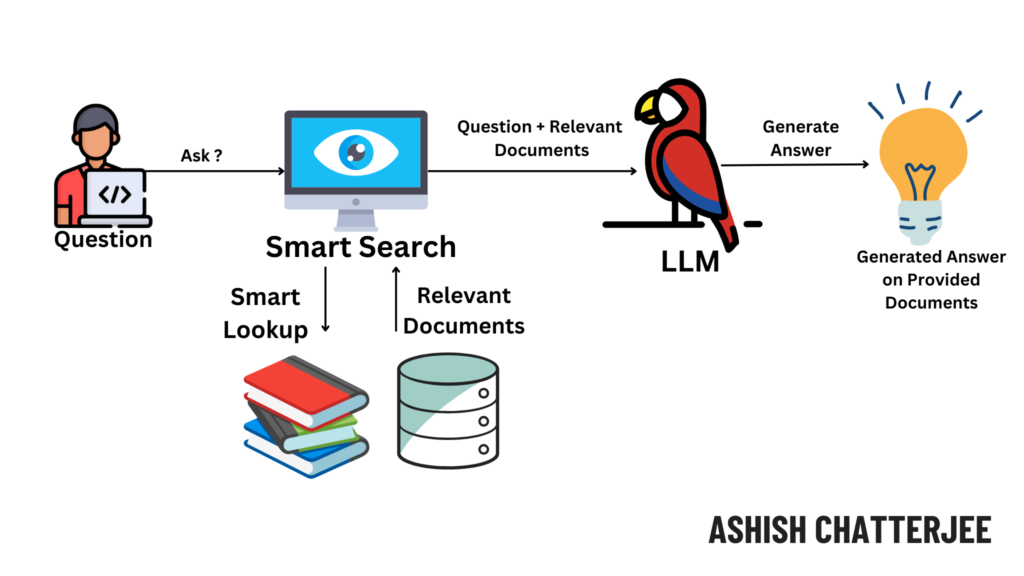
Step-by-Step Guide: Implementing Retrieval-Augmented Generation (RAG) Using Google Cloud Services
In this guide, we will build a RAG-based AI system using Google Cloud’s Vertex AI, BigQuery, and Vector Search. The system will:
✅ Retrieve relevant documents from a knowledge base
✅ Use an LLM (like PaLM or Gemini) to generate an answer
✅ Provide real-time and context-aware responses
Step 1: Set Up Your Google Cloud Project
Before implementing RAG, ensure you have a Google Cloud account and a project.
1.1 Enable Required APIs
Go to Google Cloud Console and enable the following APIs:
🔹 Vertex AI API
🔹 BigQuery API
🔹 Cloud Storage API
🔹 Cloud Functions API
Run the following command in Google Cloud Shell to enable APIs:
bashCopyEditgcloud services enable aiplatform.googleapis.com bigquery.googleapis.com storage.googleapis.com cloudfunctions.googleapis.com
Step 2: Create a Knowledge Base for Retrieval
You can store documents in different ways. Here, we’ll use BigQuery and Google Cloud Storage.
2.1 Upload Documents to Cloud Storage
If you have a set of PDFs, text files, or HTML documents, upload them to a Cloud Storage bucket:
bashCopyEditgsutil cp /local/path/to/documents/* gs://your-bucket-name/
2.2 Store Data in BigQuery (Optional for Structured Data)
For structured knowledge bases, store your data in BigQuery. Create a table with relevant fields:
sqlCopyEditCREATE TABLE `your_project.dataset.knowledge_base` (
id STRING,
title STRING,
content STRING
);
Insert sample data:
sqlCopyEditINSERT INTO `your_project.dataset.knowledge_base`
VALUES
('1', 'Google Cloud Security', 'Google Cloud provides encryption and compliance...'),
('2', 'Machine Learning in Vertex AI', 'Vertex AI allows training and deploying models...');
Step 3: Implement Vector Search for Efficient Retrieval
Since text similarity search is essential, we’ll use Vertex AI Vector Search to store and retrieve document embeddings.
3.1 Install Vertex AI SDK
Run the following command in Cloud Shell or a Jupyter Notebook:
bashCopyEditpip install google-cloud-aiplatform
3.2 Create a Vector Index
Run this Python script to create a vector index for storing document embeddings:
pythonCopyEditfrom google.cloud import aiplatform
# Initialize the Vertex AI client
aiplatform.init(project="your_project", location="us-central1")
# Create a vector search index
index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name="knowledge_base_index",
dimensions=768, # Use appropriate embedding size for your model
approximate_neighbors_count=5
)
3.3 Generate Embeddings and Store in Index
Use Google’s PaLM API (or any embedding model like BERT) to convert text into numerical vectors and store them:
pythonCopyEditfrom google.cloud.aiplatform.matching_engine import MatchingEngineIndexEndpoint
from sentence_transformers import SentenceTransformer
# Load embedding model
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
# Generate embeddings
texts = ["Google Cloud Security ensures compliance...",
"Vertex AI simplifies ML model training..."]
embeddings = model.encode(texts).tolist()
# Store embeddings in Vertex AI Vector Search
index.insert_datapoints(datapoints=embeddings, ids=["1", "2"])
Step 4: Build the Retrieval-Augmented Generation (RAG) System
4.1 Query the Vector Search Index
When a user asks a question, the system will retrieve relevant documents using vector search:
pythonCopyEditquery = "How does Vertex AI help with machine learning?"
query_embedding = model.encode([query]).tolist()
# Search for the most relevant document
neighbors = index.find_neighbors(queries=query_embedding, num_neighbors=2)
# Retrieve document content from BigQuery or Cloud Storage
retrieved_docs = [fetch_document(n.id) for n in neighbors]
4.2 Pass Retrieved Content to LLM for Response Generation
Now, we use Vertex AI’s Gemini model (or PaLM) to generate a contextual response:
pythonCopyEditfrom vertexai.language_models import TextGenerationModel
# Initialize LLM
llm = TextGenerationModel.from_pretrained("text-bison")
# Format prompt with retrieved context
context = " ".join(retrieved_docs)
prompt = f"Use the following context to answer the query:\n{context}\n\nQuery: {query}"
# Generate response
response = llm.predict(prompt)
print("AI Response:", response.text)
Step 5: Deploy the RAG System as an API
Now, let’s deploy the RAG system using Cloud Functions to make it accessible via API.
5.1 Create a Flask API
pythonCopyEditfrom flask import Flask, request, jsonify
import google.cloud.aiplatform as aiplatform
app = Flask(__name__)
@app.route('/rag-query', methods=['POST'])
def rag_query():
data = request.json
query = data["query"]
# Retrieve documents using vector search
query_embedding = model.encode([query]).tolist()
neighbors = index.find_neighbors(queries=query_embedding, num_neighbors=2)
retrieved_docs = [fetch_document(n.id) for n in neighbors]
# Generate response using LLM
context = " ".join(retrieved_docs)
prompt = f"Use the following context to answer the query:\n{context}\n\nQuery: {query}"
response = llm.predict(prompt)
return jsonify({"response": response.text})
if __name__ == '__main__':
app.run(port=8080)
5.2 Deploy the API to Google Cloud Functions
bashCopyEditgcloud functions deploy rag-query \
--runtime python310 \
--trigger-http \
--allow-unauthenticated
Now, you can send a POST request to the API endpoint:
jsonCopyEdit{
"query": "What is Google Cloud’s security model?"
}
Conclusion
Conclusion
RAG is revolutionizing AI-driven search and generation by combining retrieval with advanced language models. Its ability to provide factually accurate and context-aware responses makes it a powerful tool for industries like finance, healthcare, customer support, and legal research. With cloud-based solutions like Vertex AI, businesses can easily implement RAG to enhance their AI applications.
🔹 We successfully built a Retrieval-Augmented Generation (RAG) system using Google Cloud services.
🔹 This system retrieves relevant information from BigQuery, Cloud Storage, and Vector Search.
🔹 It enhances LLM responses by providing real-time, contextually accurate answers.
🔹 We deployed the solution as a REST API using Google Cloud Functions.



GIPHY App Key not set. Please check settings